
Talks
These are some selected presentations.
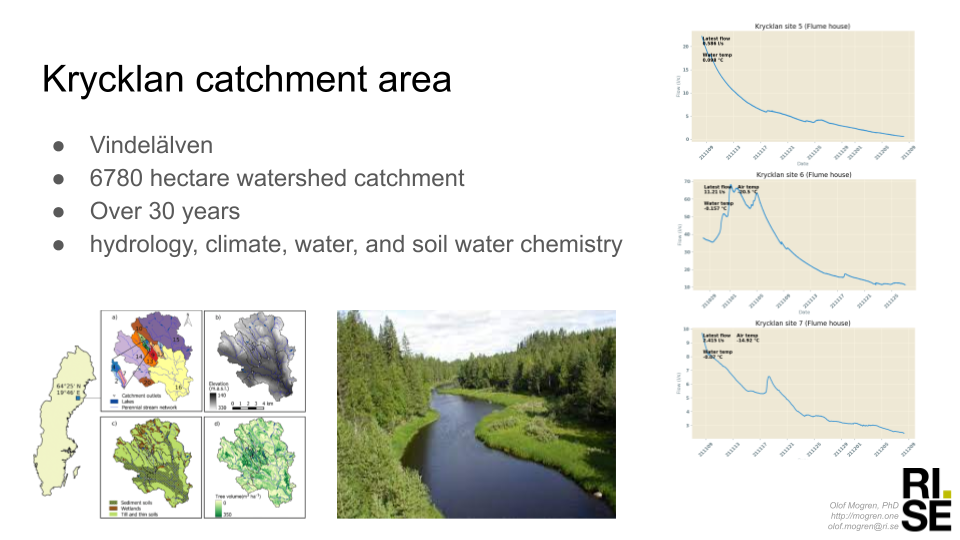



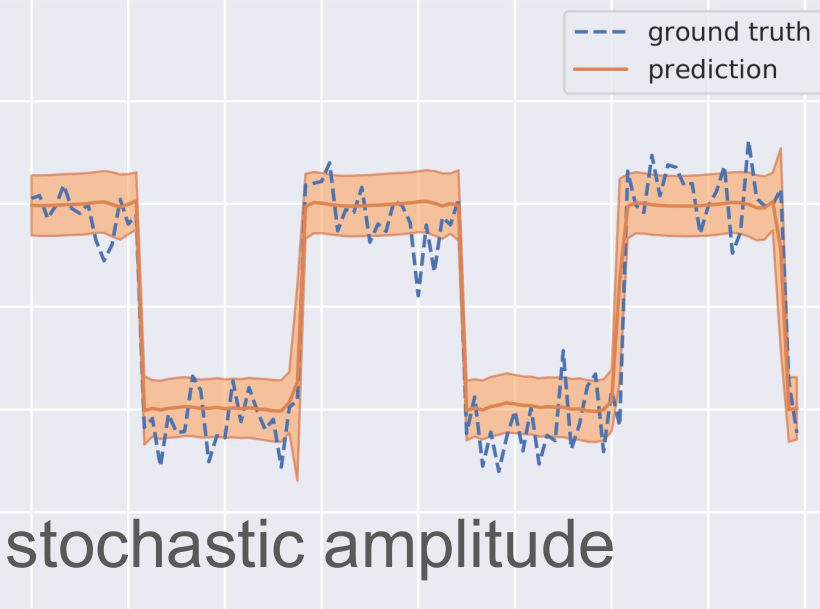



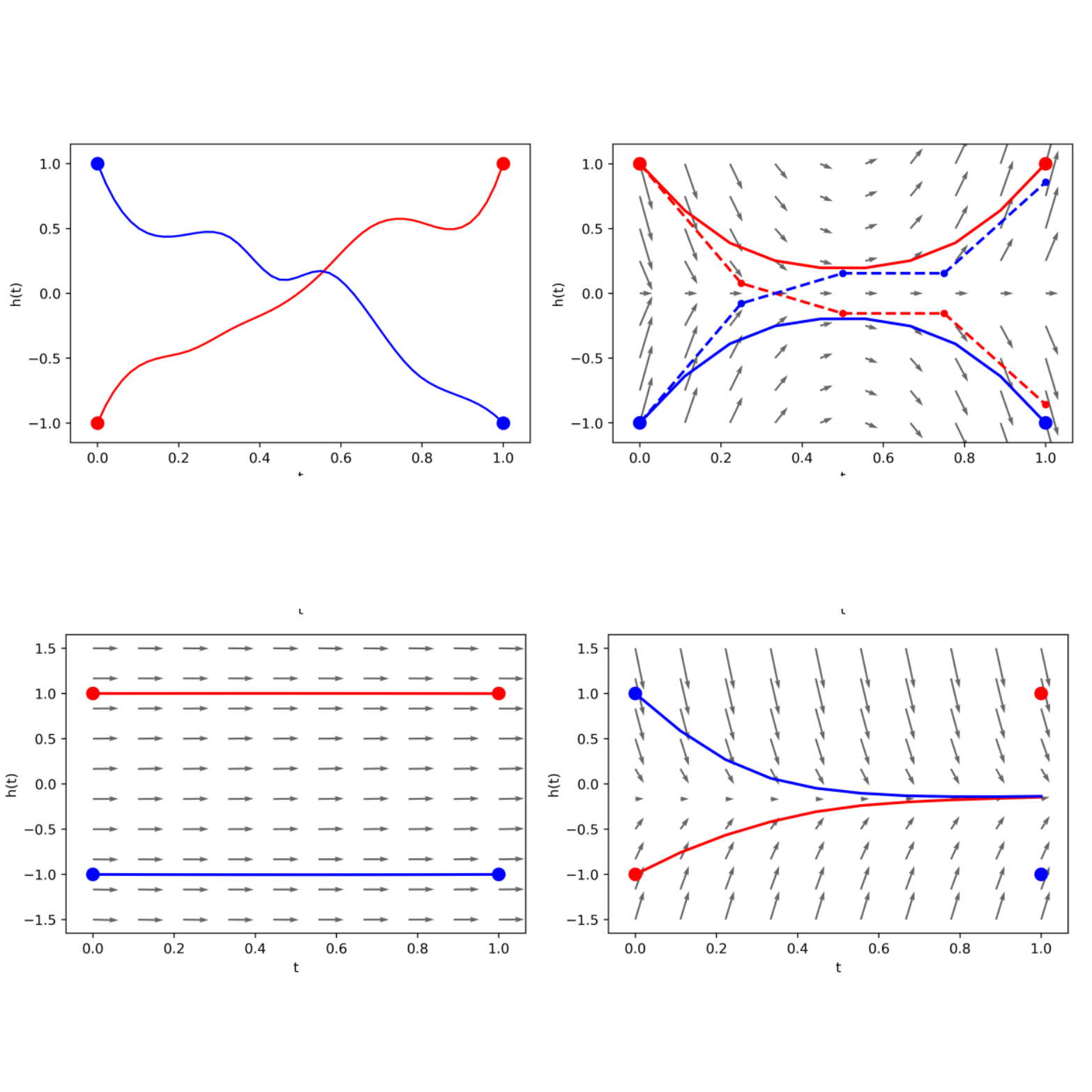



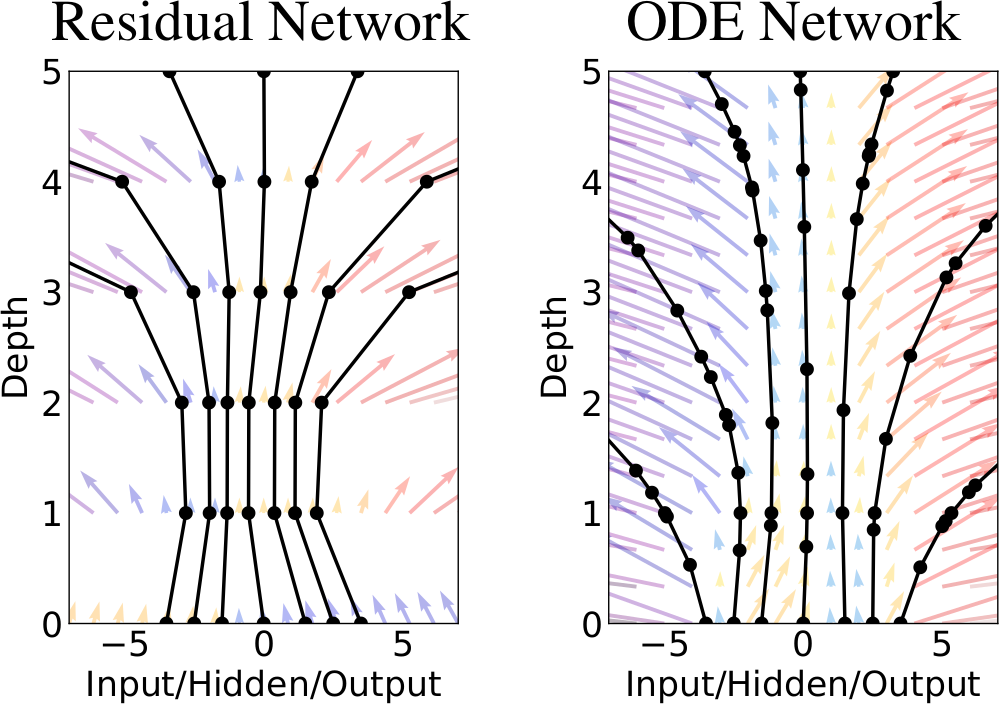






These are some selected presentations.