
First Workshop on Representation Learning for NLP
2016-08-11

On August 11th, the first workshop on Representation Learning For NLP took place in conjunction with ACL 2016 at Humboldt University in Berlin. The workshop was extremely popular, and the talks were moved to the largest auditorium to fit all visitors.
Invited talks
First out was Professor Katrin Erk from University of Texas, speaking about representations for language that is not made using deep learning, and in fact are not learned at all. This was a little bit surprising for an opening talk in a workshop on representation learning, where most titles in the proceedings contain words like “LSTMs”, “GRUs”, “RNNs” and “Neural Models”. However, Professor Erk gave a nice talk and connected distributional semantics with applications such as textual entailment and text comprehension. She gave some insights about rule-based systems, probabilistic graphical models, and generalization to unseen words.
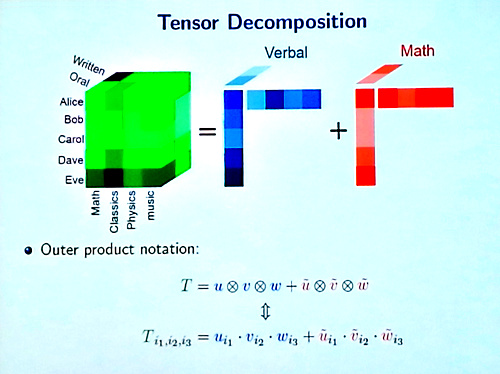
Next up was Animashree Anandkumar, Assistant Professor at the University of California Irvine, who began with a nice recap about existing techniques for learning embeddings for sentences; compositional word-representation approaches, skip-thought vectors, RNNs, and convnet approaches. The latter of these were then the focus of much of the talk, allowing for shift-invariance in language inputs. She moved on to show how these models can be formulated using tensor decomposition methods, allowing for a much faster training time. The method can then be applied to compute sentence embeddings and obtained competitive results on standard benchmarks. In summary, a truly inspiring talk.
To learn more about tensor based methods, see Animashree Anandkumar’s web page at UCI.
Besides the invited talks, three papers were awarded the best paper awards, and were given a few minutes each to introduce their work. When introdcing this session, Edward Grefenstette presented some stats: out of submissions comparable to a major conference, 37 papers were accepted to this workshop.
Best paper awards
- Mapping Unseen Words to Task-Trained Embedding Spaces, by Pranava Swaroop Madhyastha, Mohit Bansal, Kevin Gimpel, and Karen Livescu. (PDF, aclweb.org).
- A technique to handle out-of-vocabulary words. Gives improvements in downstream tasks such as dependency parsing and sentiment classification.
- Making Sense of Word Embeddings by Maria Pelevina, Nikolay Arefyev, Chris Biemann, and Alexander Panchenko. (PDF, aclweb.org)
- This paper propose a method to learn word sense embeddings, that can be initialized with traditional word embeddings. The resultng system performs comparable to state-of-the-art methods for word-sense-induction.
- Domain Adaptation for Neural Networks by Parameter Augmentation by Yusuke Watanabe, Kazuma Hashimoto, and Yoshimasa Tsuruoka. (PDF, aclweb.org)
- Using a source dataset, such as MS COCO, and a target dataset being a Japanese guidebook. The proposed method is similar to having a neural network for two tasks by attaching two output parts, but here the authors use what they call “augmented parameters”. This means that they have two output layers, with partly shared parameters. The target output uses parameter $theta_t + theta_g$, and the source output layer uses parameters $theta_g + theta_s$
Afternoon Invited Talks
Hal Daumé III, assistant professor at University of Maryland was the third invited talk. Using plenty of both enthusiasm and humour, he took us through multi-lingual word embedding approaches for problems such as transliteration. He concluded by stating that for many problems in NLP, a complex non-linear model is not needed, but you can get by with a bag of n-grams model and standard CCA. However, using multi-lingual signals are often of help, and embeddings should be given some wiggle-room.
Raia Hadsell from Google Deepmind was the last invited speaker, giving a nice talk about different approaches for representation learning, and things that you can do with the learned representations. She divided this into five different categories:
- Unsupervised learning - These are representations that we are all well accustomed to. E.g. Skipgram, gloVe.
- Supervised learning - E.g. using representations that was computed as an internal representation in a supervised model.
- Sequence modelling - RNNs, LSTMs, GRUs, etc.
- Reinforcement learning - Models that interpret the environment, control themselves, and act in their environment, trained end-to-end, e.g. Deep Q-learning. See “Demystifying Deep Reinforcement Learning” at nervanasys.com.
- Semi-supervised learning - E.g. siamese networks; needing only a measure of similarity to train.
She then moved on to talk about how things in this field are affecting each other, and lines are blurring. Examples of this are Pixel Recurrent Neural Networks by Aaron Van den Oord Google Deepmind, Nal Kalchbrenner Google Deepmind, Koray Kavukcuoglu Google Deepmind, presented at ICML 2016 (PDf, jmlr.org) as well as the Conditional Image Generation with PixelCNN Decoders by Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, Lasse Espeholt, Alex Graves, Koray Kavukcuoglu (PDF, arxiv.org), in essence considering image data as sequentially structured data.
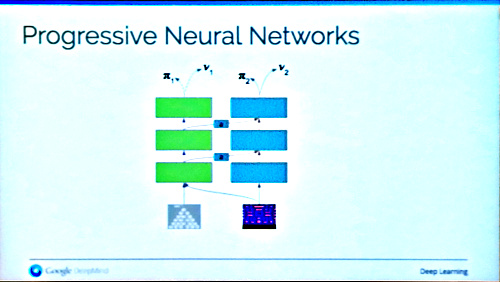
She ended her talk with Progresive nets, a way of transferring learning from one task to another, using the learning from a source task without forgetting the it, and at the same time really boosting training time to learn the target task. An example was training a system for manipulating a robotic arm, first by simulations (the source task), and then with a real robot arm (the target task).
Poster Session and Panel Discussion
During the poster session, we had our own poster titled “Assisting discussion Forum Users using Deep Recurrent Neural Networks”, showing how a recurrent neural model can be used to assist people asking questions in a discussion forum, by suggesting forum posts, discussion channels and other users that might be of help for the problem you currently express. The session was rather crowded, and many visitors came by our poster to talk, giving both interesting questions and helpful suggestions.

The whole workshop was finally concluded with a great panel discussion, chaired by Kyunghyun Cho, with all the invited speakers and also Emily Bender, Professor in Linguistics at University of Washington, and Chris Dyer from Google Deepmind. The panel made up a great mix of people with different backgrounds, and a lively discussion was held, yet a feeling of consensus appeared, and a concluding comment was that it’s OK to do NLP research coming from the linguistic side, and it’s also OK to approach linguistic problems without the linguistic assumptions, letting machines figure out how human language works.
Olof Mogren