
ACL 2016
2016-08-22
August 7-12, the 54th conference of the Association of Computational Linguistics (ACL) took place at the Humboldt University in Berlin, along with co-located tutorials and workshops. The conference was attended by roughly 1700 people, and hundreds of papers were presented during the sessions.
In this blog post, I intend to give an overview of some of the noteworthy papers presented at ACL this year. The selection is based on my own taste, in combination with my impressions from reading the papers and attending the presentations. Feel free to give me your views in the comment section in the bottom of the page.
Also see my blog posts about the Tutorial on Neural Machine Translation and the First Workshop on Representation Learning for NLP.
Monday
Generating Factoid Questions with RNNs, Iulian Vlad Serban; Alberto García-Durán; Caglar Gulcehre; Sungjin Ahn; Sarath Chandar; Aaron Courville; Yoshua Bengio
This paper presents a large corpus of 30 million question-answer pairs, designed to be used in the development of QA systems. The data is synthetically created using factoid data from Freebase and a neural model. The generated questions are evaluated and compared to questions generated by a template-based method.
Iulian Serban gave a really nice presentation, illustrating a somewhat creative solution to an interesting problem.
Achieving Open Vocabulary Neural Machine Translation with Hybrid Word-Character Models, Minh-Thang Luong and Christopher D. Manning
This paper presents a novel NMT model where out-of-vocabulary words are treated as a character sequence. The authors report big improvements in BLEU scores over models that handle OOV words by dictionary lookup, and claim that this model produces translations with better quality of the OOV translations.
When the system comes across an OOV word, it uses a deep LSTM (Wikipedia) trained on character level, always initialized with a zero state. The final internal state of this character model is used as the representation for this OOV word. The reason for the zero initialization is to make the system simple; the representation of all instances of one OOV word can be precomputed before using the word-based model. The authors show that the embeddings created by the character-based model are comparable to those learned by a normal word-based model. This comes as a nice property of the learning; no explicit learning signal is provided for this to happen.
When the word-based decoder produces an <UNK> token, the character based decoder is used. The approach is nice, and does away with some of the issues associated with neural word-based models, but still requires segmentation of the words as a preprocessing step, something that a character-based model should be able to learn. (Also see my blog post on recent trends in neural machine translation).
Improving Neural Machine Translation Models with Monolingual Data, Sennrich, Haddow, and Birch
Neural machine translation models can be viewed as language models that are conditioned on an input sentence in the source language. This work suggests that we can enhance the performance of the system, by feeding it synthetical data. The authors propose to use a monolingual training-corpus which they translate back from the target language into the source language (using a baseline NMT system trained only on parallel data), and then train the model on this synthetic parallel data, mixed with real parallel data written by human translators. The method improves the performance by up to three BLEU points. They also evaluate using other input in the encoding part, but without much improvement over the baseline. The result is interesting, as it allows for a kind of semi-supervised approach to train NMT systems, and we have the same conclusion that we are used to with neural models: having more data is more important than having high-quality data.
Together we stand: Siamese Networks for Similar Question Retrieval, Arpita Das, Harish Yenala, Manoj Chinnakotla, and Manish Shrivastava
This paper presents a convolutional neural network model that embeds posts in community question answer systems. The model uses a twin layout with tied weights and is trained by a contrastive loss function. They manage to outperform existing methods based on translation models, topic models, and some neural models. The proposed method is a rather elegant way of learning similar representations for semantically similar questions, a reasonable approach to find similar posts in a discussion forum.
Our own paper, Assisting Discussion Forum Users using Deep Recurrent Neural Networks, is related to this, but instead of convnets we use LSTMs to embed forum posts. Read more.
Tuesday
Neural Machine Translation of Rare Words with Subword Units, Rico Sennrich, Barry Haddow, and Alexandra Birch
The authors present a neural machine translation model that works on subword units to overcome the problem of words that are not part of the vocabulary. NMT systems struggle with large vocabularies, and in previous work, the handling of out-of-vocabulary words (OOV) have been primitive at best. This solution builds a vocabulary using the byte-pair encoding (BPE) (Wikipedia) algorithm, segmenting words into n-grams. In the talk, Rico Sennrich said that it can be viewed as a “character level model working on compressed character data”. This is one of at least three different papers that present work on the problem with rare words in NMT systems at this years ACL. The model is nice, rare words need no special treatment after the preprocessing of segmenting the input data, and they present good results, improving over a baseline (that handles rare words with a lexicon lookup) with roughly 1 BLEU point. (Also see my blog post on recent trends in neural machine translation).
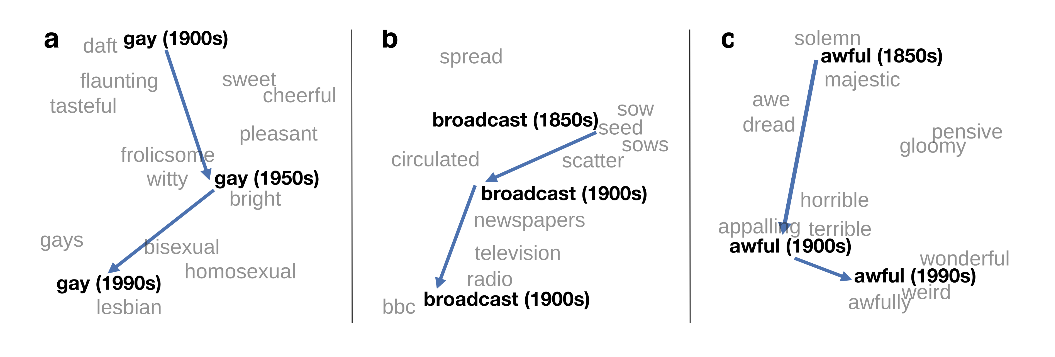
Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change, William Hamilton, Jure Leskovec and Dan Jurfsky
This work presents a nice application to use word embeddings to track the changes of semantics over time, along with some interesting observations.
A Character-Level Decoder without Explicit Segmentation for Neural Machine Translation, Junyoung Chung, Kyunghyun Cho, Yoshua Bengio
This paper presents a model trained using subword-units as inputs and a character sequence as output. The input is segmented using the byte-pair encoding algorithm as in Sennrich et.al. 2015. The character-based decoder outperforms a decoder with subword-units. Traditionally, translation systems work on word-level, even though a neural model can suffer from large vocabulary sizes. This is why we see a number of systems that try to remedy this by modelling subwords, characters, or both. (Also see my blog post on recent trends in neural machine translation).
Wednesday

ACL’s Lifetime achivement award 2016 was given to linguistics professor Joan Bresnan of Stanford who gave a nice acceptance speech about her transition from viewing natural language through the lens of formal grammars to working with probabilistic methods that model linguistic phenomena. Initially a PhD student under supervision of Noam Chomsky (Wikipedia), she spent the first part of her academic life working with grammatical formalisms, and in the 1970’s she helped to develop a theoretical formal grammatical framework called Lexical Functional Grammars, LFG (Wikipedia).
In her talk she decribed how she some years ago had a shock realizing that grammatical rules may be inconsistent with each other. With the availability of large amounts of computer-readable texts, and with inspiration from artificial neural networks and visualizations of quantitative data, she made the jump from the garden [of linguistics] into the bush [of data-driven research], as she phrased it. One of the first publications after this transition was “Predicting the dative alternation” (PDF, web.stanford.edu).
See Professor Bresnan’s own writeup of the talk here: (PDF, web.stanford.edu).
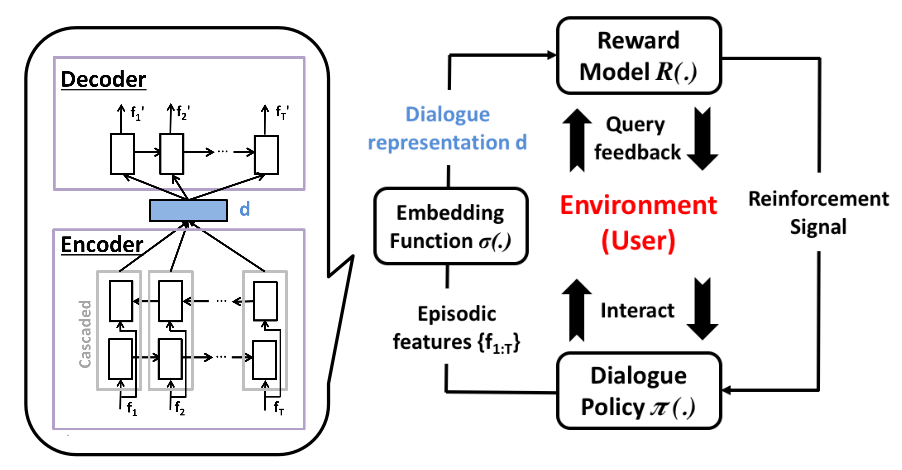
On-line active reward learning for policy optimization in spoken dialogue systems (outstanding paper), Su, Gasic, Mrksic, Barahona, Ultes, Vandyke, Wen, Young
In a task-oriented dialogue system, the user has a clearly stated goal, but training a policy-based system to provide useful responses requres a viable measure of success. This paper proposes a dialogue system based on reinforcement learning where the reward function is learned jointly with the dialogue policy. The reward function learns to model how happy the user is with the interaction, and the policy is used to generate responses.
The learned reward function operates on a fixed sized embedding of the dialogue computed using a neural sequence to sequence model with bidirectional LSTM (Wikipedia) units, trained as an autoencoder.
The poliicy optimization gets a small negative reward of -1 for each turn in the dialogue, and a large positive reward if completion is successful. The dialogue success is modelled as a Gaussian process (GP) (Wikipedia), and since getting explicit feedback from users can be costly and time-consuming, users are asked to give such feedback only if the GP model is uncertain. This feedback (coming from either the GP model, in the cases when its uncertainty estimate is low, or directly from the user) is then used as the reinforcement signal for the policy learning.
Although the policy learning uses a variant of the SARSA algorithm (Reinforcement Learning Algorithms at UNSW), the paper is a bit thin on details about how the policy is formulated and how its optimization works. The BiLSTM autoencoder (Wikipedia) is merely used to generate embeddings for the dialogue, while one could imagine building on this and letting the neural model take care of more of the interesting parts of the solution. However, the paper is well written, the idea is nice, and the presentation at ACL was very good!
Thorough examination of CNN/Daily Mail reading comprehention task (outstanding paper), Danqi Chen, Jason Bolton, Chris Manning
A nice paper showing two approaches to solve the CNN/Daily Mail reading comprehension task. The authors show that their relatively simple baseline system with a feature-based classifier beats the state-of-the-art system by more than 5%, and suggest that harder reading comprehension datasets are required. Interestingly, one day before this presentation, two related datasets were presented at ACL, the LAMBADA dataset from Denis Paperno et.al. (PDF, aclweb.org) and the WikiReading dataset for language understanding on Wikipedia from Daniel Hewlett et.al. at Google Research (PDF, aclweb.org).
The CNN/Daily Mail dataset contains article text paired with questions based on bullet point summaries from the source web pages. This paper also presents a neural system with an attention mechanism, trained to output an entity token, which beats the baseline with a small margin. (But recall that the simple baseline beats the previous state-of-the-art by a large margin)!
The paper is very well written, and the presentation was great. It’s nice to see papers where some work has gone into creating strong baselines.
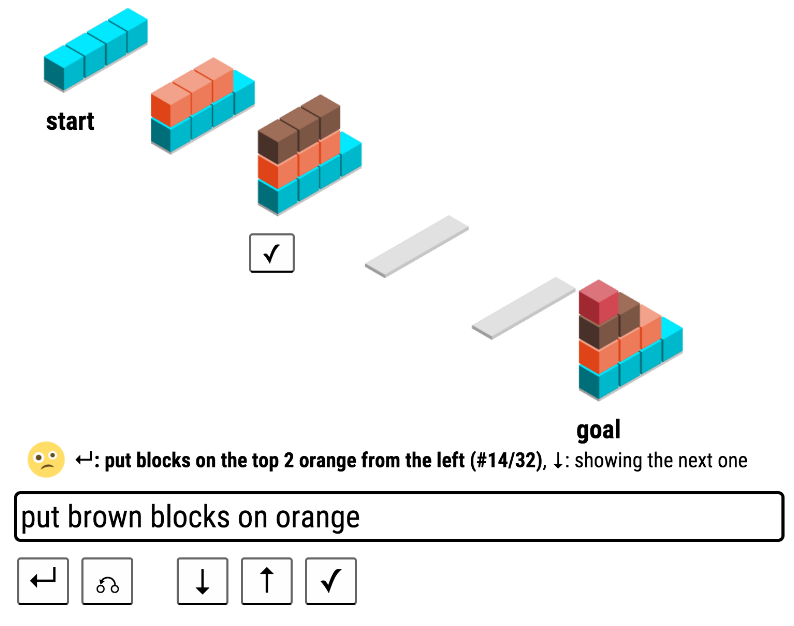
Learning language games through interaction (outstanding paper), Sida Wang, Percy Liang, Chris Manning
This paper presents a system that learns to communicate with a user based on a collaborative game inspired by the classic AI application SHRDLU (Wikipedia) (Winograd 1972). The user gives commands in their own preferred language for the application to carry out.
Initially, the computer does not know anything about the language used, or about the goal of the interaction.
The work is both a study on how computers can learn language from a collaborative interaction game, as well as on how people act in such an environment. Through Mechanical Turk (Wikipedia) users were given the task of interacting with the system.
When given a command, the computer uses what it has learned so far, and proposes some possible actions, out of which which the user can accept one.
The language learning uses n-gram (Wikipedia) features conjoined with tree-grams to represent the candidate parsing. A log-linear model over the logical forms (Wikipedia) learns to parse the utterances.
The presentation was entertaining, and the setting is interesting. The solution is applied to a rather limited setting, where you can only perform certain actions (and the actions are reasonably intuitive for the users). However, the solution is nice, and the analysis gives some insight both about strategies from human players, and what contributes to a successful outcome of the game. The system is able to adapt to different language use, but the best players also learn from the game and adapt to make the learning go smoother, e.g. by writing more consistently and lessen the use of synonyms. The setting is certainly interesting, and you can see how this could be useful for language-based interactions in some settings.
Live demo of the system (shrdlurn.sidaw.xyz).
In Conclusion
All in all, lots of interesting research was presented at ACL 2016. Around 1700 people attended the conference, up to seven sessions ran in parallel, and the interest from inustry in this field is big. Google, IBM, Amazon, Mendeley, and Maluuba were some of the companies present with booths in the exhibition hall.
Already looking forward to next year’s conference in Vancouver.
Olof Mogren