
Blood glucose prediction with variance estimation using recurrent neural networks
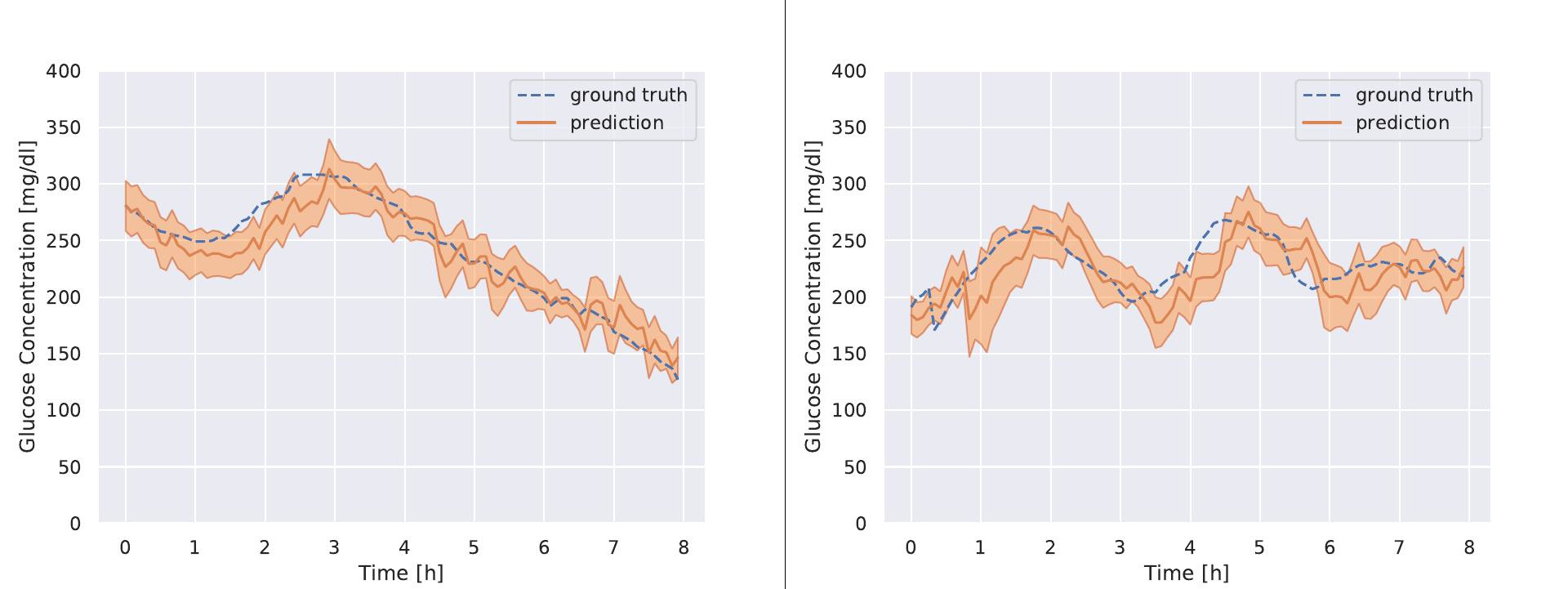
Many factors affect blood glucose levels in type 1 diabetics, several of which vary largely both in magnitude and delay of the effect. Modern rapid-acting insulins generally have a peak time after 60–90 min, while carbohydrate intake can affect blood glucose levels more rapidly for high glycemic index foods, or slower for other carbohydrate sources. It is important to have good estimates of the development of glucose levels in the near future both for diabetic patients managing their insulin distribution manually, as well as for closed-loop systems making decisions about the distribution. Modern continuous glucose monitoring systems provide excellent sources of data to train machine learning models to predict future glucose levels. In this paper, we present an approach for predicting blood glucose levels for diabetics up to 1 h into the future. The approach is based on recurrent neural networks trained in an end-to-end fashion, requiring nothing but the glucose level history for the patient. Our approach obtains results that are comparable to the state of the art on the Ohio T1DM dataset for blood glucose level prediction. In addition to predicting the future glucose value, our model provides an estimate of its certainty, helping users to interpret the predicted levels. This is realized by training the recurrent neural network to parameterize a univariate Gaussian distribution over the output. The approach needs no feature engineering or data preprocessing and is computationally inexpensive. We evaluate our method using the standard root-mean-squared error (RMSE) metric, along with a blood glucose-specific metric called the surveillance error grid (SEG). We further study the properties of the distribution that is learned by the model, using experiments that determine the nature of the certainty estimate that the model is able to capture.
John Martinsson, Alexander Schliep, Björn Eliasson, Olof Mogren
Journal of Healthcare Informatics Research
PDF Fulltext
arxiv:
bibtex.